x-pack 是什么,有什么用?自行访问官网了解即可。
x-pack的安装过程很简单,如下几步即可:
1、elsaticsearch 安装 x-pack
|
|
2、kibana 安装 x-pack
|
|
就这么两步,耐心等待安装完重启即可。这篇文章重点讲的不是安装过程,而是安装之后带来的几个坑。
x-pack 是什么,有什么用?自行访问官网了解即可。
x-pack的安装过程很简单,如下几步即可:
1、elsaticsearch 安装 x-pack
|
|
2、kibana 安装 x-pack
|
|
就这么两步,耐心等待安装完重启即可。这篇文章重点讲的不是安装过程,而是安装之后带来的几个坑。
使用Spring Data Elasticsearch连接elasticsearch时,正常情况下只需要在application.properites文件中添加如下配置即可连接:
|
|
可以看到Spring Data Elasticsearch连接elasticsearch很简单。
上面说的是正常情况,但是有些情况下连接需要验证。比如安装x-pack(旧版本的Shield、Marvel等)之后,访问elasticsearch就需要验证(未开启匿名访问),默认用户名/密码是:elastic/changeme,参考官方文档了解更多细节。
部署示例
|
|
在Jenkins(192.168.1.1)所在的服务器上面安装git,如下即可:1yum install git
配置全局name和Email
|
|
在一台电脑上同时使用多个Git账号时(如个人的Github账号和公司的Gitlab账号),有一些配置是需要注意的。否则,账号间会起冲突,使用起来有问题。
当然,如果你以HTTP(S)的方式通信(clone、push代码什么的),不会有任何问题。相信很少人这么做,毕竟每一次输入账号/密码还是很繁琐的。所以这里针对的是使用SSH的方式。
当我们第一次使用Git时,通过下面的命令来生成公钥和私钥:
|
|
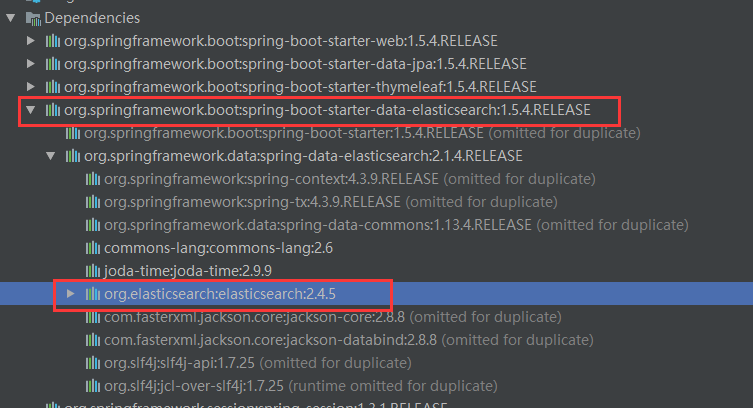
Spring Data Elasticsearch、Elasticsearch和Kibana的版本问题,很多人都应该碰到了。
我在使用Spring Data Elasticsearch时,也一样遇到了这样的问题。最开始我直接下载最新版的elasticsearch-5.4.3,然后用Spring Boot 1.5.4.RELEASE。结果你懂的,程序启动时会报客户端版本与服务端版本不一致的问题。Spring Boot 1.5.4.RELEASE中使用的elasticsearch客户端版本是2.4.5,如下图所示:
当往elasticsearch插入带时间字段的数据,然后使用Kibana查询显示这些数据时,大部分人都可能会遇到Kibana显示的时间数据与elasticsearch的时间数据不一致问题(完全相同的数据),如下:
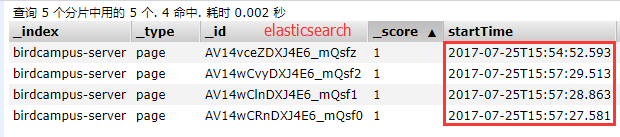
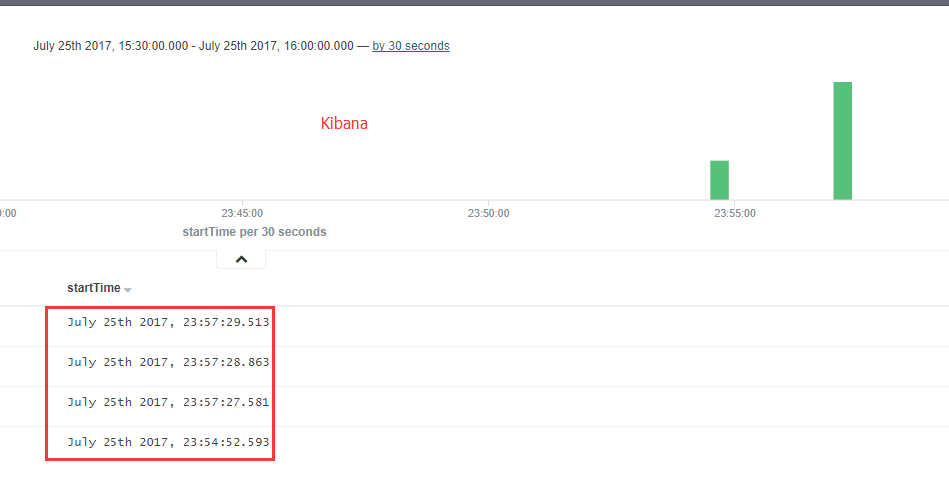
之所以会出现这个情况,是有一些原因的,这里就简单的描述下。
去官网自行下载相应的包即可,下载完后,如下解压即可:
|
|
解压后,需要自行编译,如下:
|
|
如果编译失败,可能是缺少gcc,请自行安装:
yum install gcc。
编译完成后,执行如下命令进行测试:
|
|
如果测试失败,可能是缺少tcl,请自行安装:
yum install tcl。
好产品不愁没有市场。
这是我初入社会的想法和信仰:只要有过硬的技术,开发出好的产品,自然就有未来。因此在工作的前期,我更多的是学习技术,紧跟IT潮流。 如今随着工作经验的逐渐丰富,才发现以前的想法多么单纯。
我今天想说的是:产品固然重要,但成功远远不止是做成产品这么简单!作为一名技术人,大多数人的思维都固化在“技术就是一切”的思想上,现在看来,大错特错。如今的IT技术已发展到只要你有想法,随便找一些人都能把你的想法给实现出来的地步。各种解决方案,云服务,开源的,收费的层出不穷,足够你换着花样玩。因此,想要在技术上甩开竞争对手形成壁垒是不切实际的,也就是说,在如今的大环境下,靠技术形成核心竞争力已经很难了。那靠什么来竞争,个人认为运营就是很重要的一环。
关于Office Web Apps,可以参考《在线浏览 Office 文档之 Office Web Apps》和《应用程序与 Office Web Apps 整合》。
从《应用程序与 Office Web Apps 整合》中可知,想要将自己的程序与其整合,关键在于提供如下两个接口:
1、CheckFileInfo服务,此服务会返回文件的基本信息
详情可参考[MS-WOPI] section 3.3.5.1.1 章节
2、GetFile服务,此服务根据上一个服务返回的基本信息返回对应文件的数据流
详情可参考[MS-WOPI] section 3.3.5.3.1 章节。
因此,只需要实现这两个接口即可保证office文档的在线浏览。我这里以Java为例,演示我是如何将两者整合的。
关于 字符、字符集、字符编码、ASCII、GB2312、GBK、Unicode、UTF-8等名词,这是理解乱码问题的基本,在继续往下看之前,请先理解这些概念,大家可参考此篇文章,个人觉得值得一看。
http://www.cnblogs.com/skynet/archive/2011/05/03/2035105.html
在这篇文章中,将这些名称解释的很清楚。但并没有对java编译和前后端编码、解码的场景进行分析,我这里就对这些场景进行补充。